6 Dataset
We’re using a dataset of examination results from thirty school students for demonstration and practice. For some more complicated exercises (at about the halfway mark and at the end), we will use a data set of medical trial results.
These data are in either Stata or Excel format. Each case or observation is a row with variables in columns2.
The exam data look something like this:
| surname | sex | class | maths | english | history |
|---|---|---|---|---|---|
| ADAMS | 2 | 1 | 55 | 63 | 65 |
| ALI | 2 | 1 | 52 | 46 | 35 |
| BAGAL | 1 | 3 | 51 | 58 | 55 |
| BENJAMIN | 1 | 2 | 59 | 70 | 68 |
| BLAKEMORE | 2 | 2 | 56 | 38 | 40 |
The Stata use command reads in data from Stata format files. Read the main data file by adding this command to your do file:
use https://www.ucl.ac.uk/~ccaajim/resultsWhen you first read a datafile, you should always
describethe data;- check the
codebook.
You can do this for the complete set of variables for simple cases, but you may wish to be selective when you have a lot of variables.
6.1 Data Types
The examination data is quite simple. In your do file add
describe
codebookAnd run the do file. This first command produces
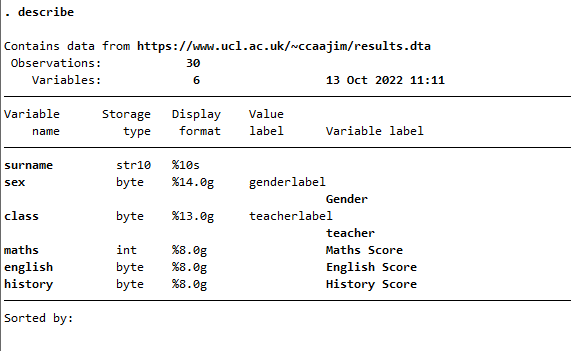
The main Stata results screen showing the output of describe
6.2 Interpretation of describe output
This output shows first how many observations there are in your data and how many variables. The table that follows includes some detail about each variable:
6.2.1 Storage type
There are two basic data types in Stata: numeric and string data. String data has two subtypes: strL (L for long) variables can store phenominal amounts of character data (2 billion) and str# (where # is a number) which a limit on length of 2045 characters. Numeric data is of one of five types:
| type | precision | range |
|---|---|---|
| byte | integer | -127 to 100 |
| int | integer | -32,767 and 32,740 |
| long | integer | -2,147,483,647 and 2,147,483,620 |
| float | real | 8 digits of accuracy |
| double | real | 16 digits of accuracy |
6.2.2 Format types
These are associated with variable types - each has a default, which determines how values are displayed, so that regardless of the precision of the type, the number of decimal places and the width in number of characters to be displayed can be fixed. So a format type %9.0g is a left justified number of maximum 9 characters in width and with specific decimal precision (although in this case zero means ‘just as many as can be displayed for this width’).
6.3 Interpretation of codebook
The output of codebook shows you the data type of the variables; the range and the numeric unit of measure; the number of unique values in the data; the number of values missing; the mean value for continuous variables; the standard deviation; the percentile values for the 10%, 25%, 50%, 75%, 90% points.
The value of output from codebook is enhanced if you have taken care to label variables and values.
Or almost, this data is in wide rather then long format, so it is not strictly tidy.↩︎